数据仓库(Data Warehouse)建模
ODS(备份)
- 保持数据原貌不做任何修改, 起到备份数据的作用。
- 数据采用压缩, 减少磁盘存储空间( 例如: 原始数据 100G, 可以压缩到 10G 左右)
- 创建分区表, 防止后续的全表扫描(一般按日期)
- 创建外部表。 在企业开发中, 除了自己用的临时表, 创建内部表外, 绝大多数场景都是创建外部表
- 构建步骤
- 用户行为数据(事件&启动),(json to string) hive单行保存
- 业务数据,hdfs to hive
DWD(清洗)
- 构建步骤
- 对用户行为数据解析
- 对核心数据进行判空过滤
- 对业务数据采用
维度模型重新建模, 即维度退化
- DWD 层需
构建维度模型, 一般采用星型模型, 呈现的状态一般为星座模型 - 维度建模一般按照以下四个步骤:
- 选择业务过程
- 声明粒度
- 确认维度(维度表)
- 原则是: 后续需求中是否要分析相关维度的指标
- 维度表: 需要根据维度建模中的星型模型原则进行维度退化
- 确认事实(事实表)
- 事实指的是业务中的度量值(次数、 个数、 件数、 金额, 可以进行累加)
- DWS 层、 DWT 层和 ADS 层都是以需求为驱动, 和维度建模已经没有关系了
- DWS 和 DWT 都是建宽表, 按照主题去建表。 主题相当于观察问题的角度。 对应着维度表
DWS(按天聚合)
- DWS 层统计各个主题对象的当天行为, 服务于 DWT 层的主题宽表
- 需要建哪些表: 以维度为基准, 去关联对应多个事实表
- 宽表里面的字段: 是站在不同维度的角度去看事实表, 重点关注事实表聚合后的度量值
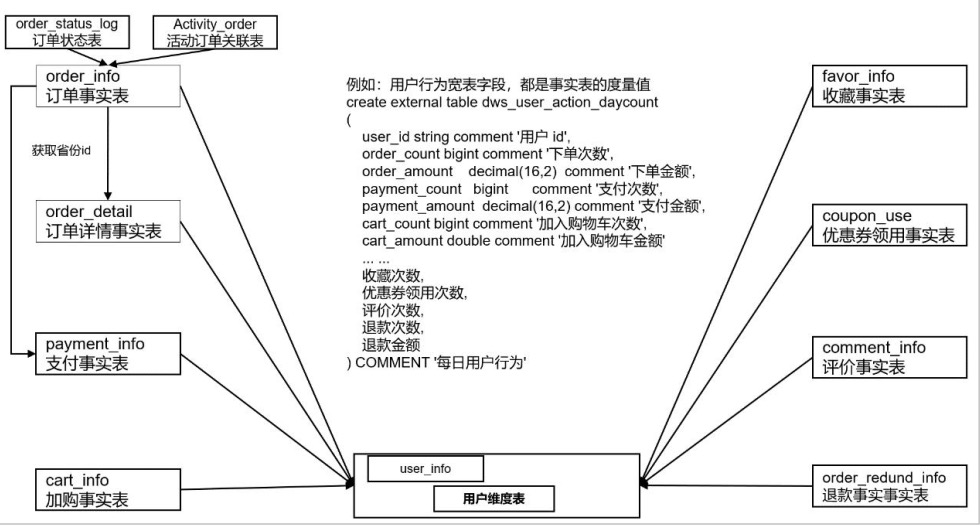
DWT(全量聚合统计)
- DWT 层统计各个主题对象的累积行为
- 需要建哪些表: 和 DWS 层一样。 以维度为基准, 去关联对应多个事实表
- 宽表里面的字段: 我们站在维度表的角度去看事实表, 重点关注事实表度量值的累积值、 事实表行为的首次和末次时间(订单事实表至今的累积下单次数、 累积下单金额和某时间段内的累积次数、 累积金额, 以及关注下单行为的首次时间和末次时间)
ADS(指标)
- 对系统各大主题指标分别进行分析
数仓命名规范
- 表命名
- ODS层命名为ods_表名
- DWD层命名为dwd_dim/fact_表名
- DWS层命名为dws_表名
- DWT层命名为dwt_表名
- ADS层命名为ads_表名
- 临时表命名为xxx_tmp
- 用户行为表, 以log为后缀
- 脚本命名
- 数据源_to_目标_db/log.sh
- 用户行为脚本以log为后缀; 业务数据脚本以db为后缀
表分类
- 日志表
- 启动日志表
- 事件日志表(根据事件类型区分)
- 业务表
- 维度表
- 全量表
- 特殊表
- 事实表
- 周期型快照事实表
- 每日快照,全量导入
- 周期型快照事实表存储的数据比较讲究时效性, 时间太久了的意义不大, 可以删除以前的数据
- 事务型快照事实表
- 一旦产生不会变化,只需导增量
- 累计型快照事实表(!!难点,动态分区,sql复杂)
- 用事件开始的时间作为分区
- 用于跟踪业务事实的变化
- 拉链表(!!)
- 用户维度表
- 修改频率不高,属于缓慢变化维度
- 用户维度表
- 周期型快照事实表
- 维度表
维度表和事实表
- 维度表
- 一般是对事实的描述信息。 每一张维表对应现实世界中的一个对象或者概念
- 维表的特征
- 维度表的范围很宽(具有多个属性、 列比较多)
- 跟事实表相比, 行数相对较小: 通常< 10 万条
- 内容相对固定: 编码表
- 事实表
- 事实表中的每行数据代表一个业务事件( 下单、 支付、 退款、 评价等) 。 “事实” 这个术语表示的是业务事件的度量值( 可统计次数、 个数、 件数、 金额等) , 例如, 订单事件中的下单金额
- 每一个事实表的行包括: 具有可加性的数值型的度量值、 与维表相连接的外键、 通常具有两个和两个以上的外键、 外键之间表示维表之间多对多的关系(外键+度量值)
- 事实表的特征:
- 非常的大
- 内容相对的窄: 列数较少
- 经常发生变化, 每天会新增加很多
关系建模和维度建模
- 数据处理分类
- 联机事务处理 OLTP( on-line transactionprocessing)
- 保证数据一致性,避免冗余
- 联机分析处理 OLAP( On-Line Analytical Processing)
- 联机事务处理 OLTP( on-line transactionprocessing)
| 对比属性 | OLTP | OLAP |
|---|---|---|
| 读特性 | 每次查询只返回少量记录 | 对大量记录进行汇总 |
| 写特性 | 随机、 低延时写入用户的输入 | 批量导入 |
| 使用场景 | 用户, Java EE 项目 | 内部分析师, 为决策提供支持 |
| 数据表征 | 最新数据状态 | 随时间变化的历史状态 |
| 数据规模 | GB | TB 到 PB |
- 维度建模
- 星型模型
- 标准星形只有单层级
- 性能优先
- 减少维度就是减少join、减少shuffle
- 雪花模型
- 多层
- 灵活优先
- 星座模型
- 星型模型
同步策略
- 全量表: 存储完整的数据。
- 增量表: 存储新增加的数据。
- 新增及变化表: 存储新增加的数据和变化的数据。
- 特殊表: 只需要存储一次
即席查询
- OLAP(Online Analytical Processing)多维分析
- ROLAP(Relational OLAP)
- 基于关系型数据库
- MOLAP(Multidimensional OLAP)
- 需要预计算
- 基于多维数据集(一个多维数据集成为OLAP Cube(立方体))
- Cuboid(长方体)
- Star Schema(星型模型)
- Dimension(维度)
- Measure(度量)

