项目需求
- 数据输入
- 用户行为数据采集
- 业务数据采集
- 数据存储
- 数仓分层
- 维度建模&报表指标
- 数据输出
- 采用即席查询进行指标分析
- 系统监控
- 集群性能监控&异常报警
- 元数据管理
- 质量监控
思考题
1. 技术选型
- 考虑因素
- 数据量大小
- 业务需求(用户数据、业务数据)
- 行业内经验(避免走弯路,借鉴)
- 技术成熟度
- 开发维护成本(CDH版本等)
- 总成本预算
- 数据采集传输
- Flume
- 擅长读取日志文件
- 相较于Logstash,行业内使用Flume更多
- Kafka
- 削峰
- Sqoop
- 转换mysql
- Logstash
- 没有大数据的公司专门用来处理日志
- DataX
- 和Sqoop市场占有率 50%:50%
- Flume
- 数据存储
- MySql
- HDFS
- HBase
- 快速插入
- Redis
- MongoDB
- 爬虫数据
- 数据计算
- Hive
- Tez
- 基于内存
- Spark
- Flink
Storm- 没落,淘汰
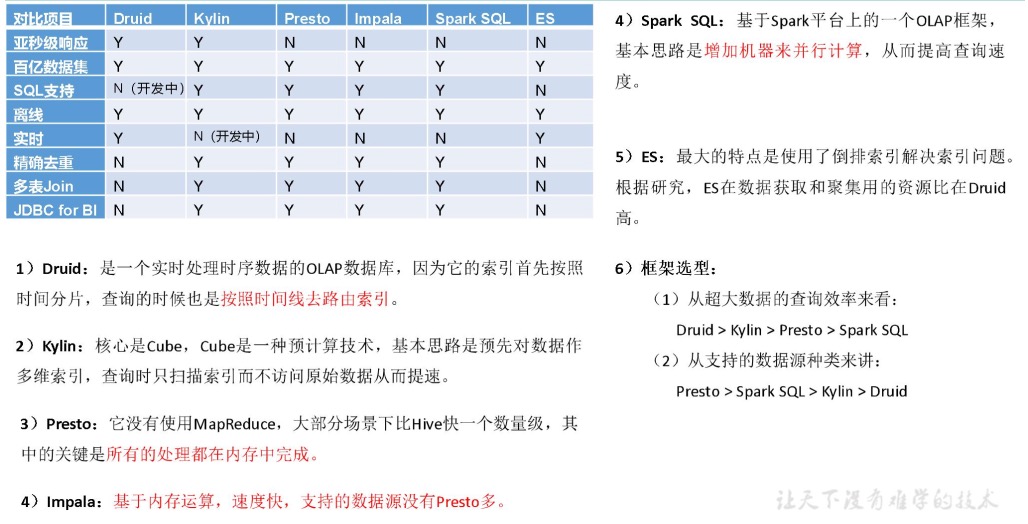
数据查询
- Presto
- 快速查询,支持多数据源
- 若是apache则选择
- Druid
- Impala
- Presto的竞品
- cdh优先选择
Kylin
- 多维查询,聚合
- Presto
- 数据可视化
- Echarts
- 百度开源,开发要求较高
- Superset
- 难度低
- QuickBI
- 离线指标,阿里开源,收费
- DataV
- 可视化大屏,阿里开源,收费
- Echarts
- 任务调度
- Azkaban
- 简单实用
- Oozie
- 功能多
- Azkaban
集群监控
- Zabbix
- Prometheus(没有历史包袱的建议选择)
| Zabbix | Prometheus |
|---|---|
| 后端用 C 开发,界面用 PHP 开发,定制化难度很高。 | 后端用 golang 开发,前端是 Grafana,JSON 编辑即可解决。定制化难度较低。 |
| 集群规模上限为 10000 个节点。 | 支持更大的集群规模,速度也更快。 |
| 更适合监控物理机环境。 | 更适合云环境的监控,对 OpenStack,Kubernetes 有更好的集成。 |
| 监控数据存储在关系型数据库内,如 MySQL,很难从现有数据中扩展维度。 | 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合。 |
| 安装简单,zabbix-server 一个软件包中包括了所有的服务端功能。 | 安装相对复杂,监控、告警和界面都分属于不同的组件。 |
| 图形化界面比较成熟,界面上基本上能完成全部的配置操作。 | 界面相对较弱,很多配置需要修改配置文件。 |
| 发展时间更长,对于很多监控场景,都有现成的解决方案。 | 2015 年后开始快速发展,但发展时间较短,成熟度不及 Zabbix。 |
- 元数据管理
- Atlas
- 数据质量监控
- Griffin
- Shell
- Python
2. 框架版本选择
- Apache
- 灵活,操作难度高
- 无管理工具
- CDH
- 管理工具,Cloudera Manager(闭源)
- 操作简单,但由于Cloudera不在维护免费版,故不推荐
- HDP
- 管理工具,Ambari(开源)
3. 服务器使用物理机or云主机
- 预算充足 + 专业运维 = 物理机
- 预算不足 | 短期产品开发迭代 | 无专业运维 = 云主机
4. 如何确认集群规模(假设:每台服务器8T磁盘,128G内存)
- 假设每天日活100W,每人一天平均100条数据:100W*100=1亿条
- 每条日志1K,每天1亿条:1亿/1024/1024=100G
- 半年内不扩容服务器来算:100G*180天=18T
- 保存3副本:18T*3=54T
- 预留20%~30%=54T/0.7=77T
- 77T/8=10台服务器
- 如果考虑数仓分层,采用数据压缩,需另行计算
集群服务器规划原则
- hdfs namenode 和 yarn resource manager分开
- 服务间通讯紧密放一起
- 服务内存资源占用多的分开
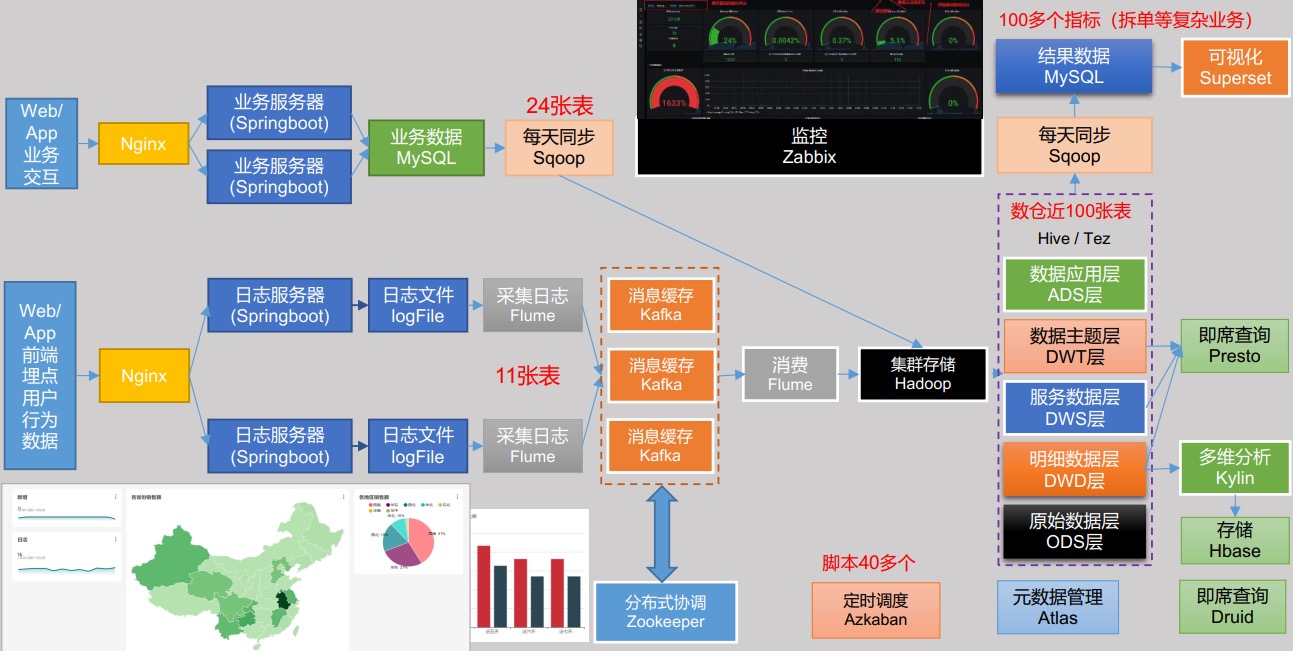
架构图
- Zabbix换成Prometheus